发布日期:2025-10-13 18:53 点击次数:175
【大河财立方记者王宇史冰倩】9月27日,2025网易未来大会在杭州举行,主题为“以智能.见未来”。作为“第四届全球数字贸易博览会”的组成部分之一,本次大会聚焦人工智能各领域的发展,探索未来趋势。
在大会中,香港理工大学人工智能高等研究院院长、加拿大工程院及加拿大皇家科学院院士杨强发表了题为《AI落地的数据难题与联邦大模型的解决方案》的主题演讲。他指出,当前AI技术虽高速发展,但也面临多重结构性挑战,亟需新的技术路径予以破解。
杨强指出,AI发展存在明显的不平衡现象。一方面,硬件性能遵循“摩尔定律”稳步提升;另一方面,AI算法与模型能力的演进速度远超硬件进步,导致软硬件之间出现日益扩大的“能力鸿沟”。与此同时,数据供给的增长速度也远低于AI对数据需求的爆发式增长。传统依赖人工标注和清洗的数据生产方式难以满足机器对海量数据(603138)的需求,未来数据短缺可能成为制约AI发展的关键瓶颈。
杨强指出,AI的发展快速程度与硬件进步速度之间存在巨大鸿沟,而数据供给的增长速度远落后于AI对数据需求的爆炸式增长,这将导致AI发展遭遇瓶颈。而且人工智能落地过程中也面临诸多前所未有的挑战——数据隐私、安全与孤岛问题。
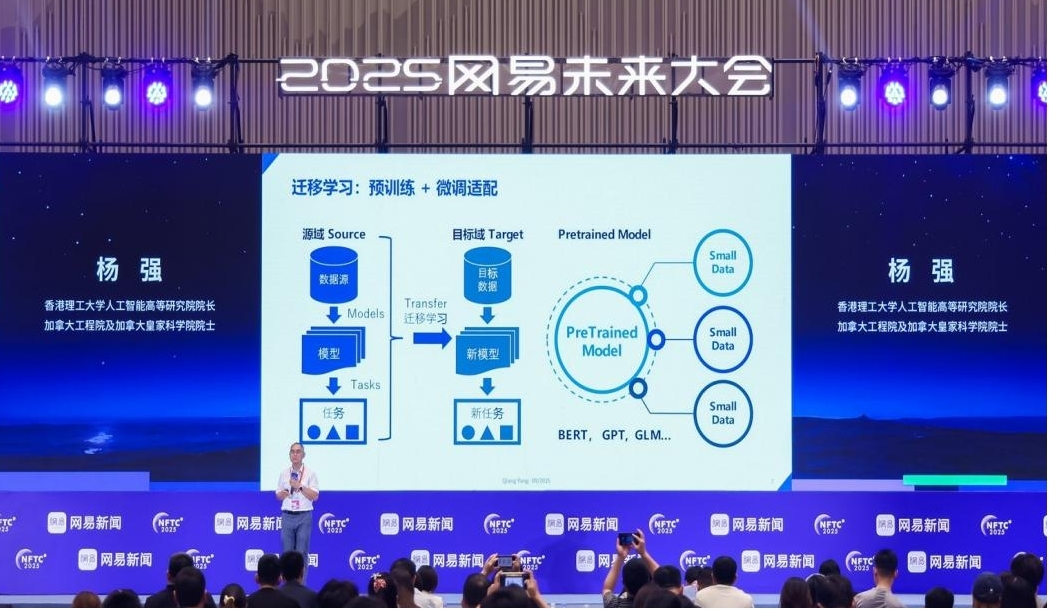
为此,杨强分享了一项研究成果:构建一个由云端通用大模型与本地垂域模型协同的架构。如何利用这些本地的私域数据来赋能通用大模型,同时让通用大模型来指导本地推理和应用,从而产生双向合作?
第一,迁移学习使模型具备举一反三的能力,不仅能突破领域限制,还能实现时间维度的迁移,确保以前建立的旧模型持续适用,并允许新模型对旧模型进行增强。
第二,运用联邦学习技术。它不仅适用于终端设备间的协作,更在企业间合作、金融风控、医疗分析等场景中具有广阔应用前景。同时,结合迁移学习与知识蒸馏,大模型可作为“教师”指导小模型提升性能,小模型也可将垂直领域知识反哺大模型,实现双向知识流动,提升整体智能水平。
据了解,联邦学习是一种隐私数据保护的机器学习方法,该方法允许多方在不共享原始数据的前提下协同训练模型,有效保障用户隐私与数据安全。
“同时,联邦持续学习可以解决模型在时间序列中出现的灾难性遗忘问题。”杨强说,新学知识会覆盖旧知识,就像“狗熊掰棒子”一样,这种现象在大模型当中非常普遍,联邦持续学习是应对这一问题的有效解法。
杨强指出,通过大模型与小模型的协同可生成新型智能体,应用于客服、个性化对话及ToB领域的供应链、风控与工作流管理等。相关技术如智能体工厂、联邦学习与持续学习已逐步集成软件系统解决方案,推动构建安全、可靠、保护隐私的分布式AI架构。
责编:陶纪燕|审校:张翼鹏|审核:李震|监审:古筝